9 Tearing down data walls
Robert Frost’s poem “Mending Wall” was a staple of John’s high school literature classes. At first read the poem is about neighbors repairing a damaged wall because “Good fences make good neighbors” (Frost 2022). However, the narrator also questions the need for a wall:
What I was walling in or walling out,
And to whom I was like to give offense.
Something there is that doesn’t love a wall,
That wants it down.
This chapter is about walls in environmental data science - in particular walls that are unconsciously constructed over a project’s lifecycle. The future of science is open (see Chapters 1 - 3) - and arguably any walls between the data, analyst, and consumer of science should be as permeable as possible. For example, The National Ecological Observatory Network’s Ecological Forecasting Challenges utilize sophisticated cyberinfrastructure technology to provide observations of ecosystems with low latency1 (Thomas et al. 2023). Understanding how to make what we call a “data wall” permeable is the focus of this chapter. Let’s begin.
9.1 What types of walls exist?
Figure 9.1 illustrates a hypothetical data wall that typically exists in a data science project, even when following the recommended practices in Chapter 5. Concerns with documentation, access, and provenance to the data collected, contributed code, and generated results all prevent other users from accessing your wonderful work. Let’s discuss each one separately.
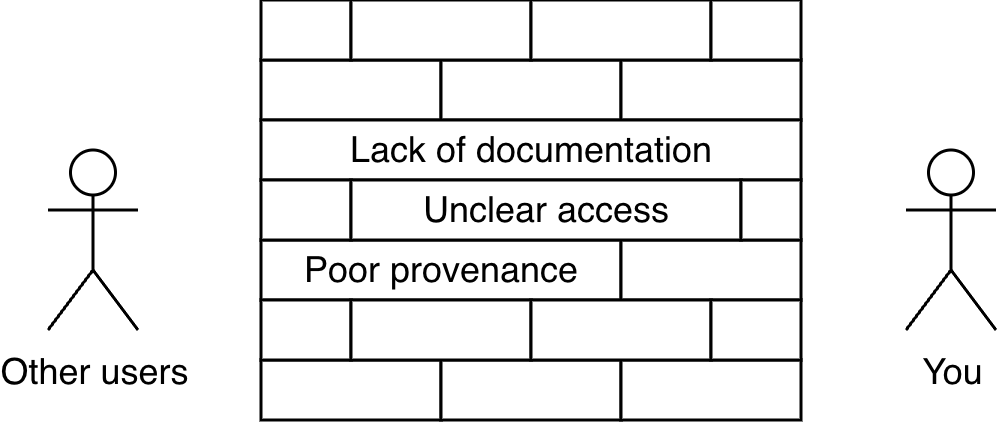
9.1.1 Documentation
Documentation helps work be translatable outside of any use-case scenarios developed by you. When writing code one often comes into a particular coding style, perhaps adapting to the conventions particular to a coding language (The Turing Way Community 2025; Heilmann 2012; Wickham and contributors 2023). Arguably not conforming to a particular style, or having dense and verbose code, creates a self-imposed data wall for other users.
Apart from coding, documentation of datasets also imposes another wall. Two examples in environmental science come to mind:
- carbon flux measurements may be measured with units of μmol m\(^{-2}\) s\(^{-1}\) (usually for half-hourly measurements at a single location) or gC m\(^{-1}\) d\(^{-1}\) (usually for integrated daily measurements)
- remote sensing measurements from MODIS typically are provided in formats to optimize storage, and so converting them to a raw number requires knowing the particular scale factor associated with that remote sensing product
Understanding how your data are measured and what additional transformations need to occur before analysis begins is the impetus for incorporating to good practices for metadata and other data conventions. By not conforming to these practices you are engaging in so-called data littering. One possible standard is ecological metadata language (EML) (Jones et al. 2019). Along with climate and forecast data conventions, adhering to EML and associated documentation, has the potential to provide robust intercomparison across datasets and ecological forecasting products (Weber et al. 2010; Dietze et al. 2023)
We recommend that especially at the onset of a project when data are first incorporated, a commensurate amount of time is needed to understand the data dictionary associated with the dataset. Scheduling that up-front work is a very grounding activity, saving yourself some time so you don’t have to backtrack your understanding. Other types of documentation include sample use case scenarios with function documentation, or adequate comments in a script file. We will discuss documentation more in Chapter 18, but as a minimum standard, documentation helps provide a good understanding of the process or actions taken steps through a code.
Programming is communication, and you want to provide enough documentation that doesn’t obfuscate what you accomplished. There are no standard ways where documentation can be provided - sometimes it is within a README file, or within a separate notes file. We recommend reviewing those files first before advancing forward with an analysis - many times there is a historical timeline that you can use and adjust. Peer review of datasets (Mayernik et al. 2015) is another useful tool prior to publication.
Beyond good local documentation, we also encourage you to consider places where you can share your (well-documented) data, code, and results. We discuss this more in Chapter 19 and Chapter 20, but open code has no shortage of examples that can be remixed. The contributed code on CRAN (and other online sources through github, or ROpenSci) provides a treasure trove of resources to advance your own project.
9.1.2 Access
Understanding data access is another factor in a data wall. At face value, data can be considered to be a collection of facts (Olson 2021), which are protected in the United States by copyright law. It is the assemblage of data in a systematic manner is what we define as information. The person(s) who assemble those data are legally responsible for how access to it as managed.
While this legal definition of data is important, we argue understanding rights and responsibilities to the data more important. Licensing data leads into consideration of open-access or creative commons licenses. We will discuss more about the different types of licenses later in Chapter 19, but for now it is important to know that these licenses exist and are useful to understand how data are shared.
9.1.3 Provenance
Finally, issues of provenance also contribute to the data wall. We term provenance as the record of the origin of data and its evolution to its current state (Tilmes et al. 2011). Modeling products and derived outputs are often removed from the point of collection, but that doesn’t necessarily mean provenance should not be considered.
At a minimum we recommend separating out raw data from processed data, and have separate script files that detail more of the origin and provenance of all data collected. In this way you, and future users will be able to follow the provenance of the data. This also helps with the long time horizon of projects - your future you will thank you!
9.2 Pathways forward
Now that you understand some of the ways that a data wall is constructed, let’s identify some guiding principles to reduce layers in that wall.
One commonly used standard for data science projects is that they should conform to the FAIR (findable, accessible, interoperable, and reproducible) principles of data management (Wilkinson et al. 2016). Most of the datasets that we have utilized through our careers (and described in previous chapters), do conform to these guiding principles.
But there is a deeper conversation to be had that although your data may be considered FAIR, it may not also consider the cultural context in which these data were collected. For example, the scientist Dr. Leke Hutchins de-identified some of the invertebrate data in his study to protect the indigenous sovereignty of where the data were collected (Pennisi 2022). For this example the FAIR principles were not the most appropriate standard for his project. In contrast, the CARE principles of indigenous data governance are one pathway that could provide greater nuance in how to consider environmental data in the context of indigenous knowledge (Carroll et al. 2021, 2020).
- C: collective benefit
- A: authority to control
- R: responsibility
- E: ethics
A notable contrasts between the FAIR principles of data stewardship and the CARE principles is how the data are centered. The CARE principles have more of a focus on principles that center people and purpose (how individuals and communities are affected), versus principles that center data (how will the data are stored in perpetuity); a helpful diagram comparing the FAIR and CARE principles can be found in Figure 1 of Carroll et al. (2020). These principles are becoming recommended practices by professional organizations (“IEEE Recommended Practice for Provenance of Indigenous Peoples’ Data” 2025).
Figure 9.2 displays a revised schematic of Figure 9.1, illustrating the possibilities that could occur when either the FAIR or CARE principles of data governance are applied. These principles do not necessarily destroy the wall between you and other users.2 Adherence to these principles may help mitigate any harms that may come from poor documentation, inadequate understanding of ownership, or inadequate provenance. Environemntal science data have been - and invariably will be - collected on traditional, ancestral lands of indigenous peoples. Implementing the CARE principles into earth systems environmental data is an ongoing conversation (Jennings et al. 2025) that intersects across several different domains of power (D’Ignazio and Klein 2020).

9.3 Always be mending
The shared wall in Frost’s “Mending Wall” requires ongoing attention for the gaps in it:
No one has seen them made or heard them made,
But at spring mending-time we find them there.
Addressing documentation, ownership, and provenances with FAIR and CARE principles are good first steps to removing walls in data science. We also recognize that this is an ongoing process that requires constant attention throughout a project. In later chapters we will revisit strategies for data documentation (Chapter 18), sharing code and data (Chapters 19 - 20), writing (Chapter 21), and deciding authorship (Chapter 22).
9.4 Exercises
Create a “Data Diary”: Over the course of one day annotate the types of places/websites to where you give up your own personal data. To help you, it might be helpful to group them in terms of the following categories:
- Search & Information
- Social media
- Games - Entertainment (streaming)
- Geographic information (maps; geolocation services)
- Other (be sure to specify)
Select one of the companies from your Data Diary and examine their End User Agreement or Terms of Service. Scan this long, legal document. Explain how your data is being used (if mentioned)?
Which of the companies from your Data Diary was the BEST example of the FAIR principles? CARE principles?
Which should be valued more: data that are “open by default” or data where the user has an “authority to control”? Explain your position and the reasons why this is the case, taking into consideration the CARE principles of Indigenous Data Sovereignty.
Many datasets assume the underlying data are “representative” of the population studied. However, demographic diversity in medical studies are hard to achieve. Which should be valued more: (1) compulsory collection of data that maximizes demographic diversity (2) protection of someone’s right to opt out of a study, even though results may be non-representative? Explain your position and the reasons why this is the case, taking into account the CARE principles of Indigenous Data Governance?
Read the chapter “The Honorable Harvest” from Braiding Sweetgrass by Robin Wall Kimmerer (Kimmerer 2013). How could you apply the principles of “The Honorable Harvest” to how data are collected and shared in today’s society, especially given the CARE principles of Indigenous Data Governance?
Latency refers to the time between a field observation to its availability for computational forecasting↩︎
Nor would you necessarily want to eliminate all walls - local control of data is important. See the position statements of the Global Indigenous Data Alliance, which promotes indigenous control of data, as well as Collaborartory for Indigenous Data Governance.↩︎