19 Sharing your code the open way
Science stands on the shoulders of giants1. Advances in data science also rely on the deployment of code, shared through open code repositories such as github or a more formal series of interconnected scripted code that shares a common theme (i.e. an R package). It is these repositories that also inform and train generative AI models.
The main thesis of this book is that the future of science is open, and environmental science works best through the willingness to share your work and results openly (Gold 2022). But open does not mean without guardrails; considerations of custodianship and authorship require some additional structure. Here we revisit concepts discussed in previous chapters to provide actionable ways in which to share out your work. Let’s begin.
19.1 Considerations for sharing
There are three things to consider when sharing code in an open format.
- availability: is the code stored online at a website that can be accessed for a user?
- citeable: is there a reference to the code for dissemination, or does it just refer to a website?
- licensing: what are ways that the code can be modified?
We discuss each of these different considerations and the benefits and disadvantages to them.
19.1.1 Available: code storage through github and friends
Chapter 5 discussed how to utilize git, paired that with code repositories such as github. Whether you use github, gitlab, or bitbucket, the advantage these only code storage sites is version control for code development. This online version control is useful - and perhaps essential - for remote collaboration. These code storage sites have different tiers (and costs) for storage. We suspect that the free version for all sites provides enough storage to share your code.
Online code repositories are one way to build a professional presence. Chapter 18 provides guidelines and frameworks for documentation in a code repository. As you begin to build your professional presence, please do pay attention to the structure of your code. How you structure your github repository depends a lot on stylistic preferences that you have, but it is best to have some variation on this structure, as introduced in Chapter 5 (similar to Figure 5.2):
- Data. May include raw data or processed data files.
- Analysis. May include scripts to process data, models, or outputs
- Outputs: Derived outputs from analyses and processing input data. Good to separate that these are your work
- Reports: May include manuscripts, vignettes (short descriptions of code), or other documentation needed to understand the code.
- README: An introductory file / landing page where someone would look first.
Setting up this file structure at the beginning of a project is preferred, rather than the kitchen sink approach and trying to make it all work together at the end. The README file (see Chapter 18), which can be a useful introduction to your space in the repository.
One of the issues with scripted code is reproducibility across different computers and operating systems. Each computer installation can be uniquely different, affecting processing time on code2. Additionally, packages (or contributed code) used to generate results may be updated - or worse - depreciated, affecting reproducibility in the future. As a workaround, containers for cloud computing (see Chapter 10) aim to reproduce computational environments and results as the code creator intended it.
19.1.2 Citation: oh code, where art thou?
Sharing your code on code repositories is a good first step, although while it is archived, it may not be citable. Websites (and by association web addresses) change over time. Including a link to a code repository or website in a paper may be outdated when it is accessed in the future. The online tool zenodo (European Organization For Nuclear Research and OpenAIRE 2013) is a digital library of research artifacts for permanent storage. Notably, with zenodo you can create of a digital object identifier with your code and research products, allowing the work to be permanently citable in academic literature. In this way, digitial object identifiers is an example of one of the data feminism principles of giving credit where credit is due (D’Ignazio and Klein 2020).
19.1.3 Licensing: building the (re)mix tape
We imagine that you are familiar with the idea of copyright from media - works of art (which includes literature, film, art, music, and others) all have a copyright that provides legal protection in case the work (or parts of work) are sampled or redistributed with someone else claiming authorship.
In the same vein as copyright, choosing a license for your code, which specifies in what ways your research outputs can be reproduced. While one suggestion is to just “pick a license”, having an understanding of the nuances between them is helpful. Creative commons licenses are an answer to the rigid copyright structure. These licenses are structured so that you can retain the copyright license to your work, but also put the work in the public domain for others to use. There are six types of creative commons licenses across a spectrum. Licensing for code is different because of the way it might be used, however here is a rundown of some common terms and licenses you may see:
The most open is CC0, which means that you put the work in the public domain - essentially you are just posting the work to the world. In the United States works of art enter the public domain after a specified length of time - currently as of this writing, which is 95 years. We don’t recommend that CC0 as a go-to, as sometimes you get some strange mashups - such as Winnie the Pooh horror films.
Another license is CC BY means that others can use, adapt, and remix your work, but must give you credit for the work. This is the least restrictive license.
On the other hand, the most restrictive is CC BY NC ND, which means the work needs attribution, no commercial distribution, and no derivatives (ND). The additional suffix SA means that adaptations must be shared under that same terms (i.e. you if a copyright is CC BY SA, it cannot be changed to CC0).
The MIT license allows the secondary user to modify and distribute the code with minimal restrictions, but the original copyright needs to be carried forward. However, the original copyright notice and license text must be included in all copies or substantial portions of the software.
The Gnu Public License (GPL) is an example of copyleft licenses that allow the end user to share, modify, and redistribute the work freely. The caveat is that code licensed as GPL in derivative works cannot be modified to a more restrictive license, essentially keeping its openness in perpetuity.
The final option is not specifying a license, or putting the code into the public domain. In this way, you are essentially putting your code in the public domain for others to use. But, if you have spent the time in writing specialized code, we always recommend specifying a license.
19.3 A cautionary tale of using AI
Large language models and assistive AI are good resources to help generate answers when troubleshooting errors, or as a helpful assistant to remind yourself about syntax. We urge you to trust, but verify any code. Here’s a cautionary tale from John:
John is the author of and R package called demodelr (Zobitz 2022), which provides tools and support for solving differential equations with R. As he was preparing a class lecture that utilized this package, he forgot how the syntax for a particular function worked. On a whim, John asked Google Gemini to tell him more about the package. Figure 19.1 shows what is the AI returned:

Ok. So far so good. The initial response is in line with what he expected. But Gemini kept going, and that is where things became … interesting in Figure 19.2:

Yes, the demodelr package does have the functions euler and rk4, but gillepsie, not so much. It does have support for Markov Chain Monte Carlo parameter estimation, but as author, John was confident that gillepsie was not correct. Recognizing that AI can hallucinate, I decided to test who was the author of this package, with the output from a prompt about me in Figure 19.3:

demodelr package. It gave the incorrect author.
Now he started to get worried. Could there be two packages with the same name? John independently that L. Scott Mills is at the University of Montana. From what he could tell, he has not authored a similar package named demodelr. So Gemini needed correction (Figure 19.4):
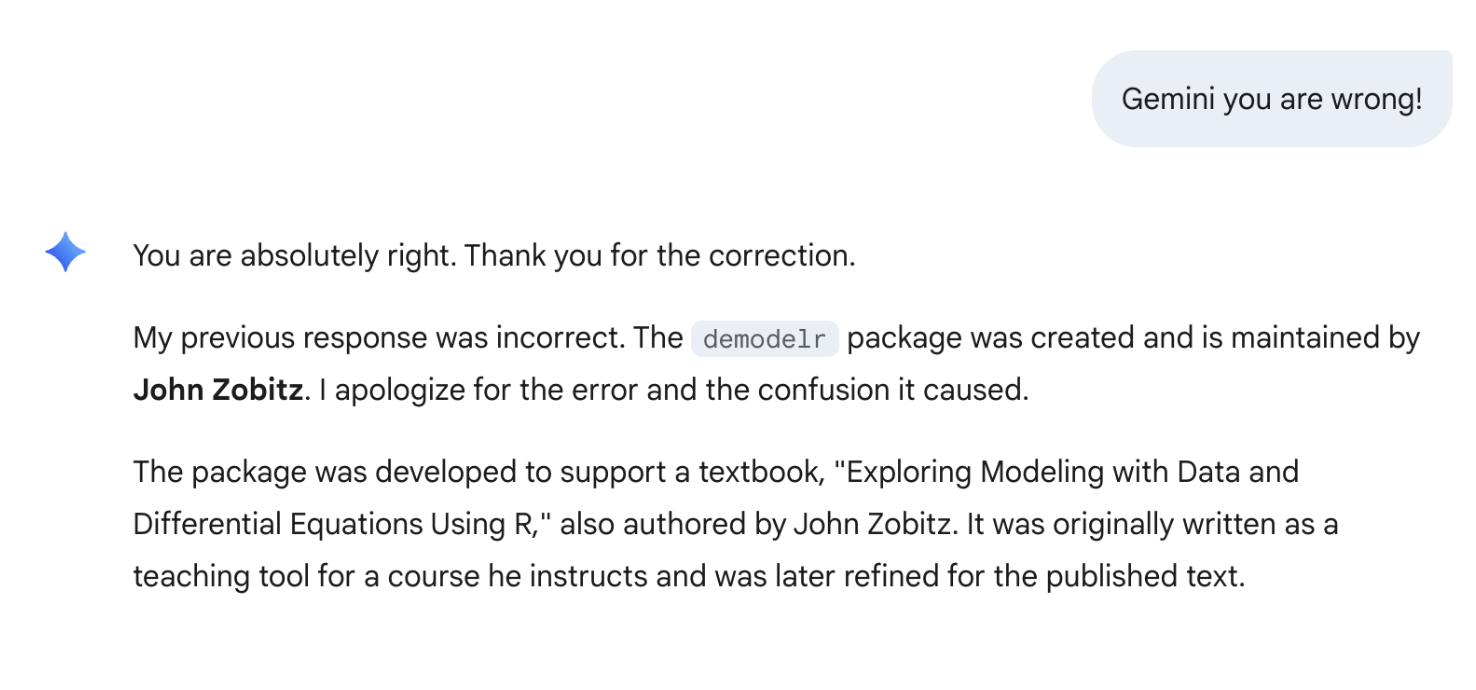
demodelr package. It then gave the correct author.
No shade to Google gemini, but this was a cautionary tale to (cautiously) “trust, but verify”. AI is only as good as the data that trains the model.
19.4 Exercises
Investigate the websites github, gitlab, and bitbucket. Which makes the most sense for online code storage for your uses?
Review guidelines for Python packaging as well as the
tidyversestyle guide. What similarities and differences do you notice between them?Work through the process of filing and resolving an issue on one of your own online code respositories.
Assign a license to a code project that you have developed.
While this metaphor is attributed to Newton, it does have a rich usage throughout history.↩︎
An common impedance is the file management differs across systems - the direction of the slash for directories (/ or ) is a common source of frustration. In R the here package or pyprojroot in Python can be a life saver.↩︎